




The 7 Biggest Misconceptions About AI Agents (and Why They Matter)
The 7 Biggest Misconceptions About AI Agents (and Why They Matter) (click to enlarge)
Image by Author
AI agents are everywhere. From customer support chatbots to code assistants, the promise is simple: systems that can act on your behalf, making decisions and taking actions without constant supervision.
But most of what people believe about agents is wrong. These misconceptions aren’t just academic. They cause production failures, blown budgets, and broken trust. The gap between demo performance and production reality is where projects fail.
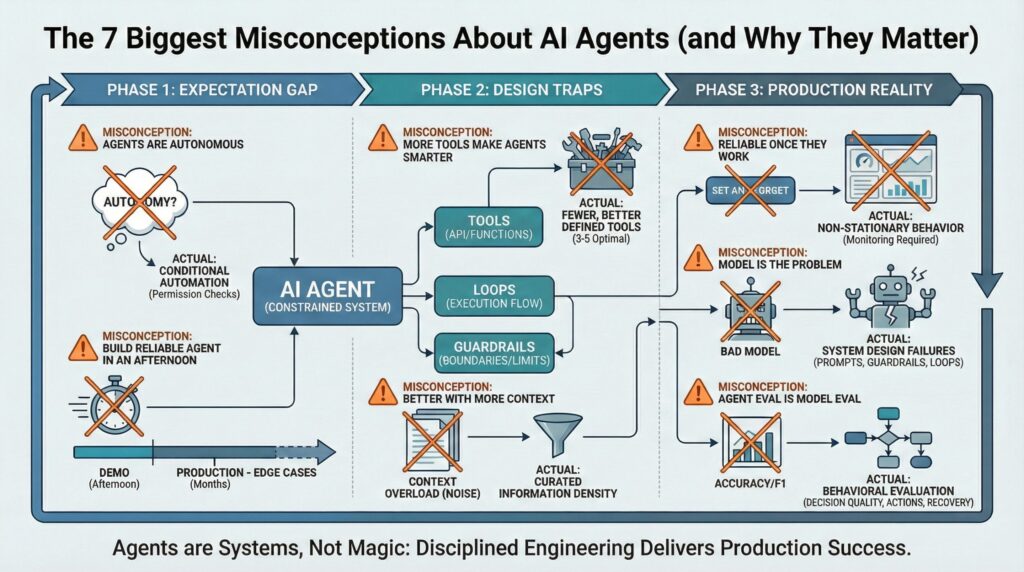
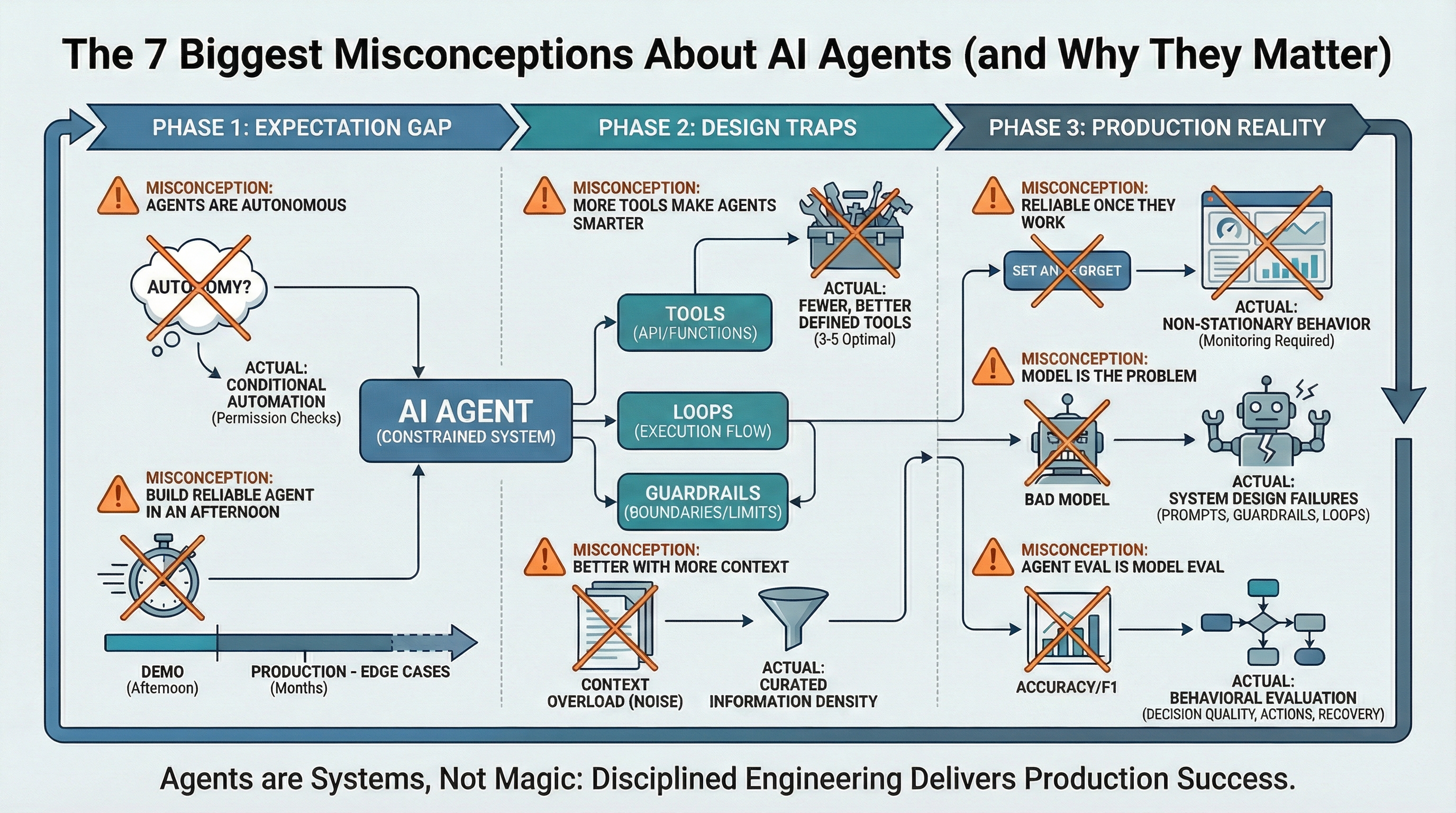
Here are the seven misconceptions that matter most, grouped by where they appear in the agent lifecycle: initial expectations, design decisions, and production operations.
Phase 1: The Expectation Gap
Misconception #1: “AI Agents Are Autonomous”
Reality: Agents are conditional automation, not autonomy. They don’t set their own goals. They act within boundaries you define: specific tools, carefully crafted prompts, and explicit stopping rules. What looks like “autonomy” is a loop with permission checks. The agent can take multiple steps, but only along paths you’ve pre-approved.
Why this matters: Overestimating autonomy leads to unsafe deployments. Teams skip guardrails because they assume the agent “knows” not to do dangerous things. It doesn’t. Autonomy requires intent. Agents have execution patterns.
Misconception #2: “You Can Build a Reliable Agent in an Afternoon”
Reality: You can prototype an agent in an afternoon. Production takes months. The difference is edge-case handling. Demos work in controlled environments with happy-path scenarios. Production agents face malformed inputs, API timeouts, unexpected tool outputs, and context that shifts mid-execution. Each edge case needs explicit handling: retry logic, fallback paths, graceful degradation.
Why this matters: This gap breaks project timelines and budgets. Teams demo a working agent, get approval, then spend three months firefighting production issues they didn’t see coming. The hard part isn’t making it work once. It’s making it not break.
Phase 2: The Design Traps
Misconception #3: “Adding More Tools Makes an Agent Smarter”
Reality: More tools make agents worse. Each new tool dilutes the probability the agent selects the right one. Tool overload increases confusion. Agents start calling the wrong tool for a task, passing malformed parameters, or skipping tools entirely because the decision space is too large. Production agents work best with 3-5 tools, not 20.
Why this matters: Agent failures are tool-selection failures, not reasoning failures. When your agent hallucinates or produces nonsense, it’s because it chose the wrong tool or mis-ordered its actions. The fix isn’t a better model. It’s fewer, better-defined tools.
Misconception #4: “Agents Get Better With More Context”
Reality: Context overload degrades performance. Stuffing the prompt with documents, conversation history, and background information doesn’t make the agent smarter. It buries the signal in noise. Retrieval accuracy drops. The agent starts pulling irrelevant information or missing critical details because it’s searching through too much content. Token limits also drive up cost and latency.
Why this matters: Information density beats information volume. A well-curated 2,000-token context outperforms a bloated 20,000-token dump. If your agent’s making bad decisions, check whether it’s drowning in context before you assume it’s a reasoning problem.
Phase 3: The Production Reality
Misconception #5: “AI Agents Are Reliable Once They Work”
Reality: Agent behavior is non-stationary. The same inputs don’t guarantee the same outputs. APIs change, tool availability fluctuates, and even minor prompt modifications can cause behavioral drift. A model update can shift how the agent interprets instructions. An agent that worked perfectly last week can degrade this week.
Why this matters: Reliability problems don’t show up in demos. They show up in production, under load, across time. You can’t “set and forget” an agent. You need monitoring, logging, and regression testing on the actual behaviors that matter, not just outputs.
Misconception #6: “If an Agent Fails, the Model Is the Problem”
Reality: Failures are system design failures, not model failures. The usual culprits? Poor prompts that don’t specify edge cases. Missing guardrails that let the agent spiral. Weak termination criteria that allow infinite loops. Bad tool interfaces that return ambiguous outputs. Blaming the model is easy. Fixing your orchestration layer is hard.
Why this matters: When teams default to “the model isn’t good enough,” they waste time waiting for the next model release instead of fixing the actual failure point. Agent problems can be solved with better prompts, clearer tool contracts, and tighter execution boundaries.
Misconception #7: “Agent Evaluation Is Just Model Evaluation”
Reality: Agents must be evaluated on behavior, not outputs. Classic machine learning metrics like accuracy or F1 scores don’t capture what matters. Did the agent choose the right action? Did it stop when it should have? Did it recover gracefully from errors? You need to measure decision quality, not text quality. That means tracking tool-selection accuracy, loop termination rates, and failure recovery paths.
Why this matters: You can have a high-quality language model produce terrible agent behavior. If your evaluation doesn’t measure actions, you’ll miss the most important failure modes: agents that call the wrong APIs, waste tokens on irrelevant loops, or fail without raising errors.
Agents Are Systems, Not Magic
The most successful agent deployments treat agents as systems, not intelligence. They succeed because they impose constraints, not because they trust the model to “figure it out.” Autonomy is a design choice. Reliability is a monitoring practice. Failure is a system property, not a model flaw.
If you’re building agents, start with skepticism. Assume they’ll fail in ways you haven’t imagined. Design for containment first, capability second. The hype promises autonomous intelligence. The reality requires disciplined engineering.
About Vinod Chugani
Vinod Chugani is an AI and data science educator who has authored two comprehensive e-books for Machine Learning Mastery: The Beginner’s Guide to Data Science and Next-Level Data Science. His articles focus on data science fundamentals, machine learning applications, reinforcement learning, AI agent frameworks, and emerging AI technologies, making complex concepts actionable for practitioners at every level.
Through his teaching and mentoring work, Vinod specializes in breaking down advanced ML algorithms, AI implementation strategies, and emerging frameworks into clear, practical learning paths. He brings analytical rigor from quantitative finance and entrepreneurial experience to his educational approach. Raised across multiple countries, Vinod creates accessible content that makes advanced AI concepts clear for learners worldwide.
Connect with Vinod on LinkedIn.


